Correlazione come divinazione? AI e conoscenza
- Paolo Benanti
- 13 mag 2019
- Tempo di lettura: 12 min
Cosa c'entra una mappa dello stato dell'Alabama di 100 milioni di anni fa con le intelligenze artificiali e il machine learning? Più volte nei post di questo blog ho fatto riferimento alla correlazione come strumento chiave per le AI. Con questo post cerco di approfondire un po' la questione. E quindi cosa c'entra l'Alabama? E la sua configurazione geologica nel Cretaceo, l'era geologica che va da 145 a 66 milioni di anni fa, come è connessa al machine learning? Temo che, per la risposta, si debba leggere il post...
Reddit e i suoi meandri
Per introdurre il nostro tema sfruttiamo un post di Reddit un sito Internet di social news e intrattenimento, dove gli utenti registrati (chiamati redditor e stimati in oltre 500 milioni al mese) possono pubblicare contenuti sotto forma di post testuali o di collegamenti ipertestuali (link). I contenuti di Reddit sono organizzati in aree di interesse chiamate subreddit e il nostro post è in un subreddit molto evocativo chiamato Mapporn. Al di là del nome il canale si occupa di mappe in alta qualità e vede discussioni varie sulla costruzione della mappa e sulla sua accuratezza.
Ecco la mappa proposta in questo post di inizio maggio 2019:

Questo il titolo della mappa:
"Lo stato dell'Alabama nel periodo Cretaceo (da 145 a 66 milioni di anni fa) confrontato con come l'Alabama ha votato nelle elezioni del 2016"
Le due mappe mostrano due condizioni molto diverse. A sinistra la conformazione orografica del territorio con indicato in verde il luogo dove nel Cretaceo c'era il mare. A destra i distretti elettorali dell'Alabama con colorati in blu i distretti dove hanno prevalso i democratici e in rosso i repubblicani. Le due mappe mostrano territori analoghi. Tuttavia una domanda ci assale:
Ma le due mappe sono confrontabili? ovvero "Hanno qualcosa a che fare l'una con l'altra o è solo una coincidenza?"
L'autore, MartyVanB, del post crede di si. Ecco la sua spiegazione:
"Per fornire un contesto alla mappa: la spiaggia del periodo Cretaceo è divenuta alcuni dei terreni agricoli più ricchi degli Stati Uniti grazie alla spiaggia che ha spinto le rocce in profondità e ha lasciato ricchi giacimenti di sostanze disciolte nel terreno che hanno portato allo sviluppo dell'industria del cotone in quest'area. Questo, naturalmente, ha condotto ad avere in questa zona grandi piantagioni con schiavi i cui discendenti rimangono in questa zona".
Ecco che, dopo la spiegazione, appare un legame. La presenza dell'acqua ha cambiato il suolo rendendolo fertile. Con le colonie le piantagioni sono nate dove il terreno era più fertile. La presenza degli schiavi è poi diventata una diversa distribuzione della popolazione che produce oggi un differente orientamento elettorale.

Gli altri utenti hanno accolto il post con evidente sorpresa.
MChainsaw così commenta: "Ho pensato che questa fosse solo una mappa scherzosa in cui avevi preso due cose completamente indipendenti che sono casualmente coincidenti, ma ci hai dato una motivazione reale per cui esiste una correlazione reale!"
MChainsaw, lui o lei che sia, ha messo subito al centro la questione di nostro interesse: cose simili ci sembrano simili. La correlazione è quella caratteristica che dici che questa similitudine è in qualche misura legata.
Un altro utente, Aadenoian, commenta: "Fa parte della "cintura nera" che è così chiamata tanto per il colore nero del suolo trovato nella regione, quanto per una popolazione nera comparativamente sproporzionata rispetto al resto degli Stati Uniti (per via della schiavitù, come affermato in precedenza)".
Se questo sembra chiudere definitivamente il tema, leggendo le reazioni al post possiamo notare almeno un altro paio di commenti interessanti.
Il primo è di brokegradstudent: "La cintura nera è anche endemicamente povera e non ha un numero adeguato di servizi igienici per i suoi abitanti". A questa ulteriore correlazione, Cretaceo, piantagioni e numero di bagni per abitante, risponde un altro utente. LeCrushinator ha scritto: "Stavo anche pensando che fosse una correlazione spuria, specialmente quest'ultima".

Viene qui introdotto un termine che analizzeremo più avanti nel post: "correlazione spuria" a cui è dedicato un famoso sito.
Chiude la discussione un altro utente, columnarjoint, "La geologia controlla gran parte del destino umano. Dal petrolio e da altre risorse naturali alla birra." Qui si registra un passaggio chiave. La discussione cambia il suo oggetto. Non è più semplicemente un dibattito se le due mappe sono in qualche misura correlate ma se una causa l'altra. Cioè se il Cretaceo ha causato il risultato elettorale del 2018.
Il tema dopo una serie di post viene così concluso. UnofficiallyCorrect scrive: "Sarebbe una correlazione senza alcuna motivazione esplicita. Forse intendevi la causalità, che fornisce un collegamento tra i dati. l'autore ha descritto la causalità che spiega perché esiste una correlazione (una correlazione è tale indipendentemente da un nesso causale)".
Questo piccolo esempio ci permette di mettere a fuoco un tema quanto mai chiave in questo momento di datificazione della realtà. Dobbiamo aver ben chiaro cosa si intende per correlazione e che relazione ci sia tra questa e la causazione.
Correlazione e causazione
Per capire la sfida della correlazione e della causazione dobbiamo ripercorrere la trasformazione che a ha subito - e che sta ancora subendo - la comunità scientifica nella parte finale dello scorso secolo.
Nei primi anni del XX secolo la comunità umana era cablata dal telegrafo e poi dal telefono. Oggi le connessioni a livello globale avvengono tramite computer: in borsa gli scambi di denaro e di merci, il controllo del traffico aereo e ferroviario, ecc. avvengono per via informatica. La stessa via consente a milioni di persone di scambiarsi messaggi senza limiti di tempo e di spazio.

La rivoluzione che hanno portato i computer e l’informatica nel campo scientifico-tecnologico è stata abilmente descritta da Naief Yehya:
con un computer possiamo trasformare quasi tutti i problemi umani in statistiche, grafici, equazioni. La cosa davvero inquietante, però, è che così facendo creiamo l’illusione che questi problemi siano risolvibili con i computer (N. Yehya, Homo cyborg. Il corpo postumano tra realtà e fantascienza, Eleuthera, Milano 2005, p. 15.).
Chris Anderson, il direttore di Wired, traccia una sintesi di cosa significhi la rivoluzione digitale per il mondo scientifico:
«gli scienziati hanno sempre contato su ipotesi ed esprimenti. [...] Di fronte alla disponibilità di enormi quantità di dati questo approccio - ipotesi, modello teorico e test - diventa obsoleto. [...] C’è ora una via migliore. I petabytes ci consentono di dire: “la correlazione è sufficiente”. Possiamo smettere di cercare modelli teorici. Possiamo analizzare i dati senza alcuna ipotesi su cosa questi possano mostrare. Possiamo inviare i numeri nel più grande insieme di computer [cluster] che il mondo abbia mai visto e lasciare che algoritmi statistici trovino modelli [statistici] dove la scienza non può. [...] Imparare a usare un computer di questa scala può essere sfidante. Ma l’opportunità è grande: la nuova disponibilità di un’enorme quantità di dati, unita con gli strumenti statistici per elaborarli, offre una modalità completamente nuova per capire il mondo. La correlazione soppianta la causalità e le scienze possono avanzare addirittura senza modelli teorici coerenti, teorie unificate o una qualche tipo di spiegazione meccanicistica» (C. Anderson, The End of Theory, Wired 16(2008) pp. 106-107).
L’avvento della ricerca digitale, dove tutto viene trasformato in dati numerici porta alla capacità di studiare il mondo secondo nuovi paradigmi gnoseologici: quello che conta è solo la correlazione tra due quantità di dati e non più una teoria coerente che spieghi tale correlazione . Praticamente attualmente assistiamo a sviluppi tecnologici (capacità di fare) che non corrispondono a nessuno sviluppo scientifico (capacità di conoscere e spiegare): oggi la correlazione viene usata per predire con sufficiente accuratezza, pur non avendo alcuna teoria scientifica che lo supporti, il rischio di impatto di asteroidi anche sconosciuti in vari luoghi della Terra, i siti istituzionali oggetto di attacchi terroristici, il voto dei singoli cittadini alle elezioni presidenziali USA, l’andamento del mercato azionario nel breve termine.
L’utilizzo dei computers e delle tecnologie informatiche nello sviluppo tecnologico hanno messo in evidenza una sfida linguistica che avviene al confine tra uomo e macchina: nel processo di interrogazione reciproca tra uomo e macchina sorgono proiezioni e scambi, finora impensati, e la macchina si umanizza non meno di quanto l’uomo si macchinizzi.

La correlazione allora è uno strumento che risulta particolarmente utile con i computer a sostegno della ricerca. Questo purché se ne conosca la natura. In statistica, una correlazione è una relazione tra due variabili tale che a ciascun valore della prima corrisponda un valore della seconda, seguendo una certa regolarità.
L'indice di correlazione di Pearson (anche detto coefficiente di correlazione lineare o coefficiente di correlazione di Pearson o coefficiente di correlazione di Bravais-Pearson) tra due variabili statistiche è un indice che esprime un'eventuale relazione di linearità tra esse.
Il coefficiente assume sempre valori compresi tra -1 e 1. Nella pratica si distinguono vari "tipi" di correlazione. Se l'indice di correlazione è >0, le variabili si dicono direttamente correlate, oppure correlate positivamente; se =0, le variabili si dicono incorrelate; se <0, le variabili si dicono inversamente correlate, oppure correlate negativamente.
Inoltre per la correlazione diretta (e analogamente per quella inversa) si distingue: se l'indice di correlazione è <0,3 si ha correlazione debole; se tra 0,3 e 0,7 si ha correlazione moderata; se >0,7 si ha correlazione forte. Se le due variabili sono indipendenti allora l'indice di correlazione vale 0.
Bisogna notare che non vale la conclusione opposta: in altri termini, l'incorrelazione è condizione necessaria ma non sufficiente per l'indipendenza.
Ecco una serie di esempi di correlazioni con il rispettivo indice di correlazione:

Tuttavia va notato che che gli indici e i coefficienti di correlazione siano da ritenersi sempre approssimativi, a causa dell'arbitrarietà con cui sono scelti gli elementi: ciò è vero, in particolare, nei casi di correlazioni multiple.
Ma se due fenomeni sono correlati sono anche legati da nesso di causalità?
Per rispondere dobbiamo tornare al concetto di causa
«Ex nihilo nihil fit»
Così sentenziava Cartesio nei suoi Principia philosophiae parlando della necessità di una causa perché qualcosa sia. La causazione infatti nasce in filosofia. Nella storia della filosofia, nella scienza e nel senso comune il concetto di causa assieme a quello connesso di causalità o relazione causale indica la relazione tra due fenomeni (o classi di fenomeni), nel caso in cui il primo fenomeno, detto causa, è motivo di esistenza del secondo, detto effetto. La causa è il motivo per il quale qualcosa è, ed è così come è.
La causazione è quindi un concetto che conosce uno sviluppo analogo a quello della filosofia e che dice un modo di comprendere la realtà e il nesso tra ciò che esiste. Non voglio qui ripercorrere la storia della causalità o delle cause da un punto di vista filosofico ma dobbiamo però almeno aver presente uno sviluppo recente che porta alla comprensione odierna della causalità.
Il meccanicismo deterministico si è oggi rivelato sostanzialmente inadatto a spiegare il mondo microscopico. Ciò deriva anche dall'aver sostituito nella gnoseologia il concetto di causa con quello di serie causale, poiché in realtà i sistemi sia fisici che biologici sono caratterizzati da un numero molto alto di variabili causali. Un effetto è perciò quasi sempre la risultante di più cause e la tipologia e il modo con cui le cause si connettono o sconnettono determina il risultato.

L'indeterminismo, la validità solo statistica delle leggi scientifiche hanno fatto considerare sorpassate le concezioni filosofiche del passato a cui si sono sostituiti nuovi modelli di interpretazione come è accaduto con la fisica quantistica che ha sostituito allo schema deterministico quello probabilistico. Il probabilismo scientifico ha pertanto sostituito il determinismo tradizionale andando a coincidere dal più al meno con l'indeterminismo.
L'introduzione del concetto di complessità ha imposto l'opportunità di associare al concetto di causa quello, specificatamente adottato ad esempio nella disciplina giuridica, di serie causale, nella quale più cause concorrono a un effetto. I sistemi complessi evolvono in maniera sia deterministica che indeterministica, soggetti a mutamenti sia casuali che necessari che vengono modernamente definiti, in particolare nell'ambito della matematica e della fisica, sistemi lineari e sistemi intricati.
Anche l'epistemologia si è chiesta quale debba essere il vero valore di conoscenza delle leggi scientifiche e se queste non esprimano altro che una funzione di utilità pratica piuttosto che un valore teoretico nell'interpretazione della natura.
Le leggi della natura vanno considerate allora come schemi sintetici in cui raccogliere le misurazioni quantitative e le previsioni sperimentali degli scienziati.
Filosofi e scienziati come Ernst Mach, Hermann von Helmholtz dalla seconda metà del XIX secolo alla prima metà del XX hanno teorizzato la sostituzione del concetto di causalità nelle scienze con quello di descrittività per cui le leggi scientifiche si limiterebbero a descrivere sinteticamente quanto avviene in modo costante ed uniforme nei fenomeni naturali.
Alle leggi scientifiche non spetta più il compito di spiegare i fenomeni usando pretese oggettive relazioni di causalità ma di descrivere soggettivamente le sequenze uniformi ricorrendo a necessarie costanti verifiche empiriche.
Queste teorie convenzionalistiche e lo stesso operazionismo di Percy Williams Bridgman però sono state criticati così che oggi la fisica teorica e l'epistemologia, pur mantenendo il carattere della descrittività delle leggi scientifiche, sono alla ricerca di un nuovo concetto di causalità.
Causalità nell'epoca dei dati: la correlazione spuria
Se la causalità è in crisi tanto da un punto di vista filosfico/epistemologico che scientifico la matematica può essere uno strumento abbastanza descrittivo da fungere da funzione supplente a questo gap teorico. Questo è il motivo filosofico che sostiene l'esito che Anderson ha descritto sulla pagine di Wired,

La statistica e i suoi assunti logici cercano di fornire una funzione e di supplenza aspettando che nuove comprensioni della causalità e della realtà ci permettano di continuare questo viaggio umano nella conoscenza del mondo.
Questo è il punto dove oggi la filosofia serve alla tecnica: se le macchine trovano correlazioni e "decidono" in base ad esse, dobbiamo poter avere dei criteri di verifica e di comprensione per evitare esiti indesiderati per le AI e il machine learning. Questi infatti utilizzando algoritmi di regressione sono sistemi di tipo correlativo
Parlando di strumenti statistici bisogna essere coscienti che nel cercare una correlazione statistica tra due grandezze, per determinare un possibile rapporto di causa-effetto, essa non deve risultare una correlazione spuria.
La correlazione spuria venne descritta nel 1926 da George Udny Yule in Why Do We Get Some Nonsense Correlations Between Time Series? A Study in Sampling and the Nature of Time Series, dopo aver notato in uno studio una correlazione lineare positiva tra percentuale di matrimoni con rito religioso e tasso di mortalità.
Rilevando anno dopo anno il numero di matrimoni e il numero di rondini in cielo, si può osservare ad esempio una forte correlazione tra i due fenomeni, il che non è dovuto al fatto che uno dei due influenza l'altro, ma semplicemente al fatto che in certi paesi le rondini compaiono durante le loro migrazioni in primavera ed autunno che sono pure i periodi preferiti dalle coppie nello scegliere il giorno delle nozze.
In altri termini se due fenomeni risultano statisticamente correlati tra loro, non vuol dire necessariamente che tra di essi sussista un legame diretto di causa-effetto, potendo essere tale correlazione del tutto casuale (cioè spuria) ovvero dipendente da una terza variabile in comune, in assenza di meccanismo logico-causale plausibile che li metta in relazione tra loro.
Ecco una divertente galleria di alcune correlazioni spurie:



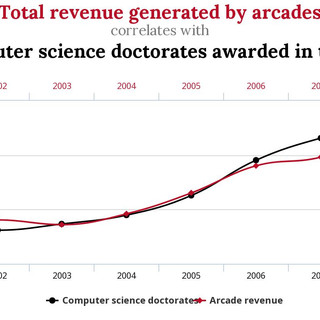



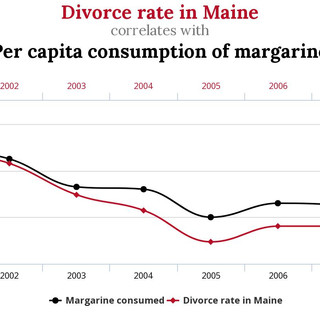

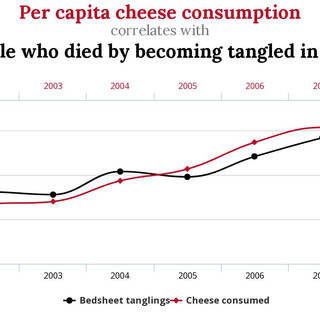

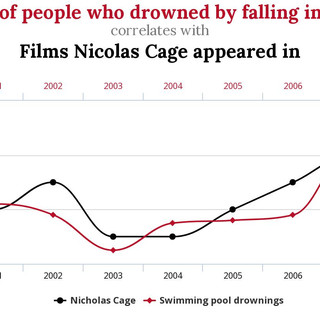
Oracoli?
Proprio la natura di provocazione a pensare di questo post mi impedisce chiudere questo contributo con delle conclusioni. Quello che ho scritto vuole essere un invito ad aprire delle piste di riflessioni condivise.
Da quando non solo abbiamo imparato a vedere la realtà come un insieme di dati ma abbiamo anche imparato a collezionarli, i big data, ci siamo dotati di un nuovo strumento di indagine. Tre secoli fa con le lenti concave abbiamo realizzato il telescopio e il microscopio, imparando a vedere il mondo in modo diverso. Microsocpio e telescopio costituirono gli strumenti tecnologici con cui la rivoluzione scientifica del 600 e del 700 ha ottenuto le sue scoperte. Abbiamo reso visibile l'estremamente lontano telescopio - e l'estremamente piccolo - microscopio -.
Oggi con i dati abbiamo realizzato un nuovo “strumento” il macroscopio. Con i big data noi riusciamo a vedere in maniera nuova e sorprendente l'estremamente complesso delle relazioni sociali individuando relazioni e connessioni dove prima non vedevamo nulla. Le AI e il machine learning applicati a questi enormi set di dati sono il macroscopio con cui studiare meccanicisticamente l'estremamente complesso. Spetta a noi capire che tipo di conoscenza stiamo generando. Se questa forma di conoscenza sia scientifica e in che senso sia deterministica o predittiva è tutto da capire. Tuttavia la rivoluzione conoscitiva, come con il telescopio e il microscopio, è già in atto.

Infine guardiamo al modo con cui approcciamo i database e i big data. I big data sono dei database che raccolgono enormi quantità di diversi tipi informazioni che vanno dai testi all’audio, dai video alle immagini, dai like su Facebook alle transazioni monetarie, e che richiedono l’utilizzo di calcolatori estremamente potenti per riuscire a gestirli. Dalla straordinaria capacità di elaborazione di questa sterminata moltitudine di elementi in formato digitale, che l’umanità ha spontaneamente riversato online negli ultimi decenni, si possono estrapolare delle previsioni. Sempre di più, almeno nell'attività lavorativa, i dati sono diventati una meta sicura: i numeri non mentono, rispondono sempre e sono sempre disponibili. Per chi sa cose domandare un database è l’interlocutore ideale. Ma oggi si può fare molto di più: i dati sono in grado di fornire risposte a domande che non siamo in grado di fare. È questo, in fondo, il risultato più innovativo di quella scienza nascente che si chiama big data, ovvero la capacità di raccogliere dati eterogenei e di individuare relazioni, collegamenti, connessioni inaspettate. Le aspettative sono elevatissime e molte aziende sono impegnate nella costruzione di questo grande oracolo personale. Per il momento soprattutto accumulano dati, tanto che le quantità di informazioni archiviate stanno crescendo a ritmi travolgenti. Si comincia già a parlare dell’era dei BrontoByte, un’unità di misura dei dati fino a qualche anno fa inimmaginabile, ma a cui già oggi si avvicinano alcune organizzazioni che anni accumulano instancabilmente byte da ogni fonte.
La vera sfida, però, è far parlare questo nuovo oracolo digitale, capire cosa ci dice. Ci sembra una curiosa coincidenza che una delle maggiori società leader nella catalogazione dei dati e negli strumenti per studiare e gestire i database si chiami Oracle, cioè oracolo.
Allora i dati diventano gli dei del XXI secolo. Sono loro i vati e gli oracoli da interrogare per sapere i segreti che sono nascosti nel nostro futuro. E diviene quanto mai significativo un frammento di uno dei primi filosofi, Eraclito, con cui abbiamo aperto questo teso. Il filosofo di Efeso avverte: “Il signore, il cui oracolo è a Delfi, non dice né nasconde, ma significa” (Sulla natura frammento 93). Oggi i dati offerti in modo sacrificale agli idoli delle AI significano, cioè indicano, senza spiegare.
È urgente pensare le AI e gli algoritmi per farlo dobbiamo tornare a quella forma matriciale del nostro pensiero occidentale la polis greca, la piazza in cui far convergere i diversi saperi in cerca della verità. E allora sono le parole di Baricco, nel suo racconto City, forse l’apertura migliore al compito che ci aspetta:
Tutte quelle storie sulla tua strada. Trovare la tua strada. Andare per la tua strada. Magari invece siamo fatti per vivere in una piazza, o in un giardino pubblico, fermi lì, a far passare la vita, magari siamo un crocicchio, il mondo ha bisogno che stiamo fermi, sarebbe un disastro se solo ce ne andassimo, a un certo punto, per la nostra strada, quale strada? sono gli altri le strade, io sono una piazza, non porto in nessun posto, io sono un posto.



留言